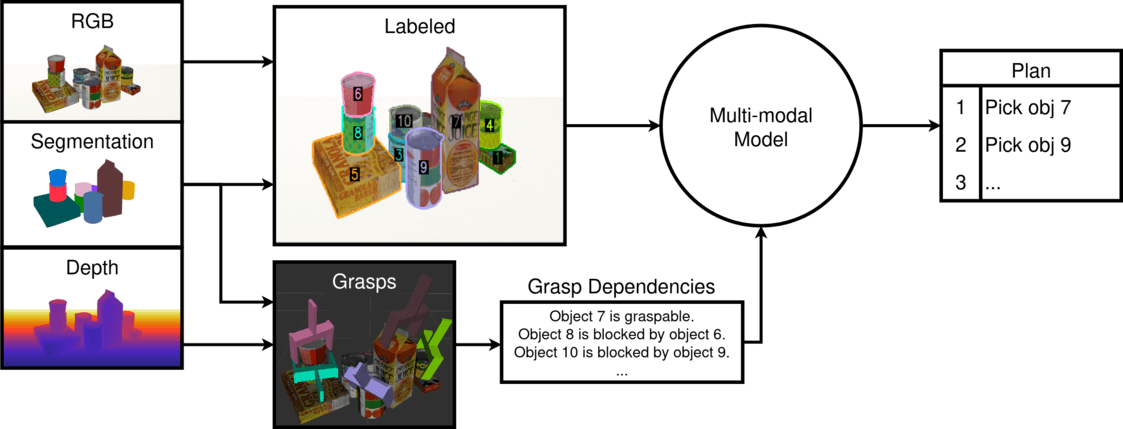
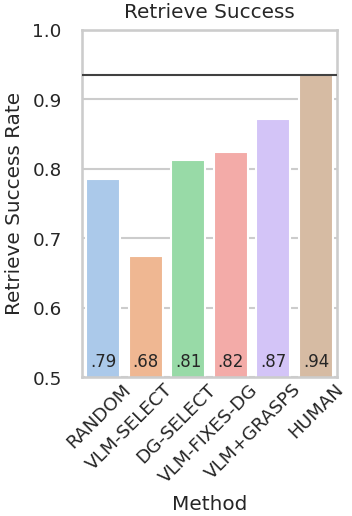
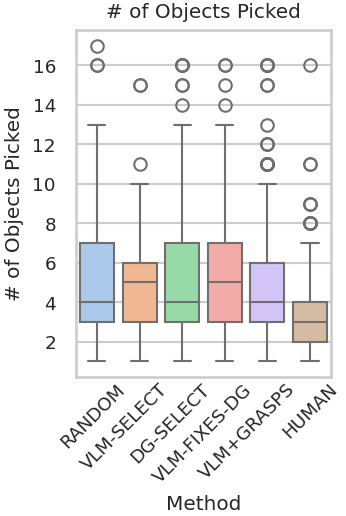
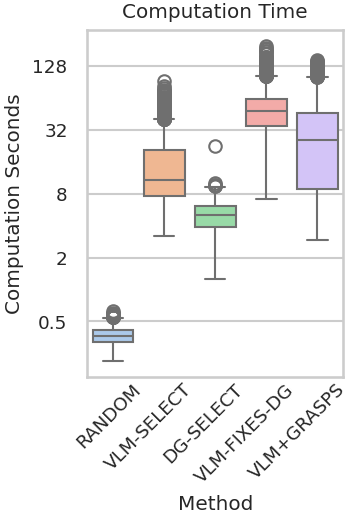
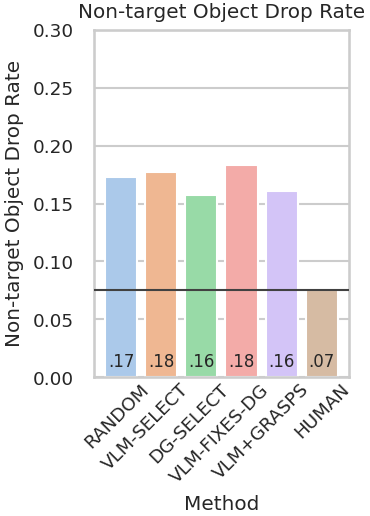
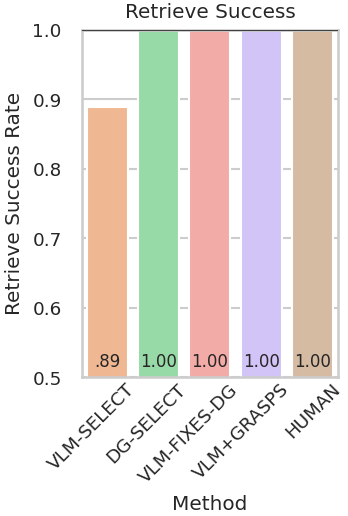
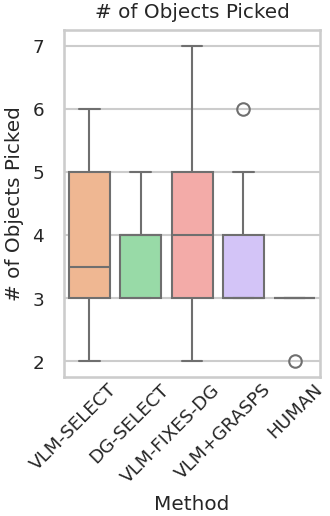
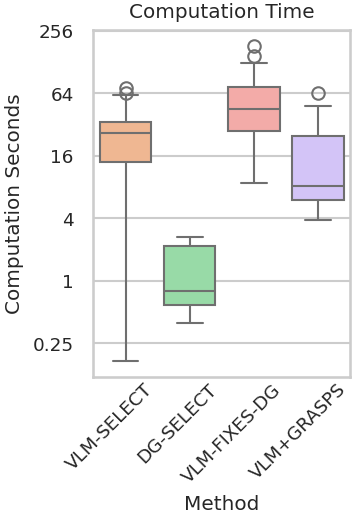
Abstract
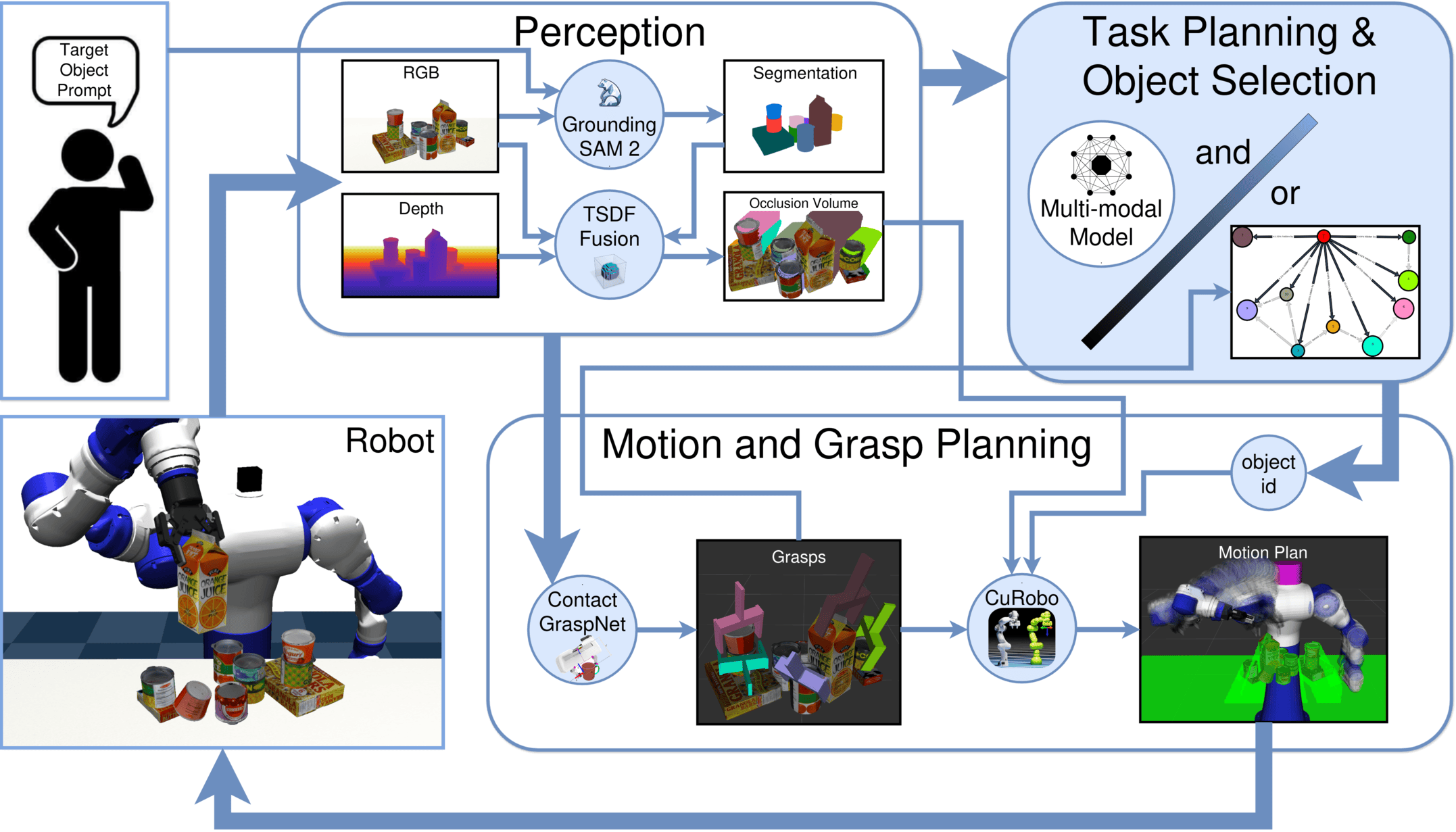
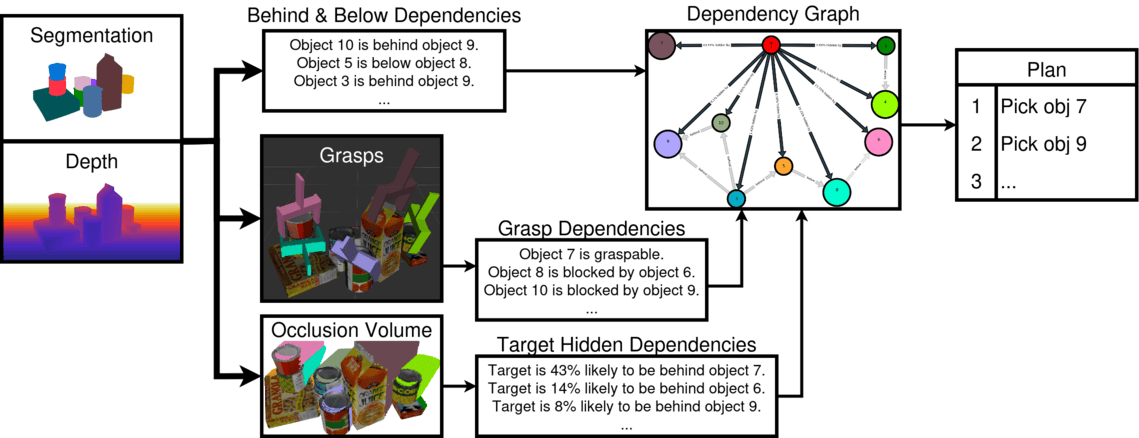
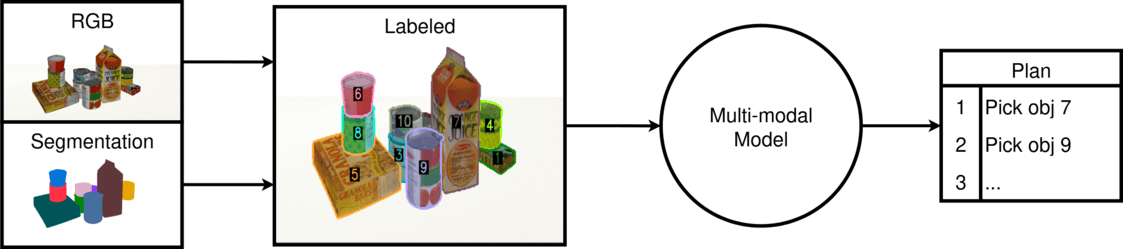
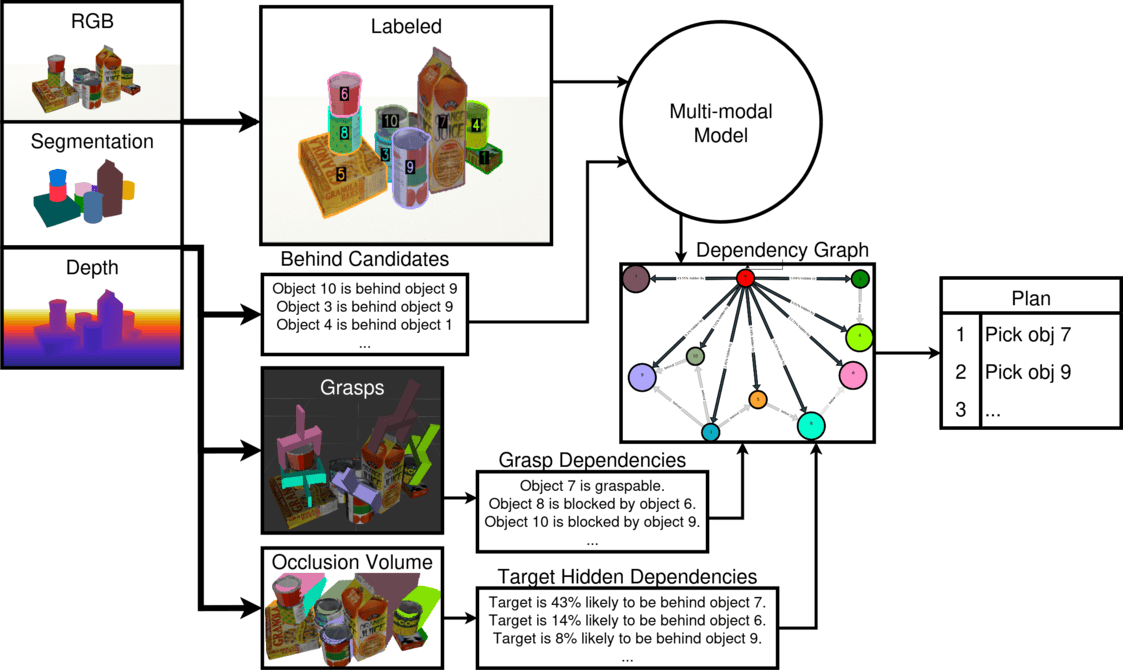
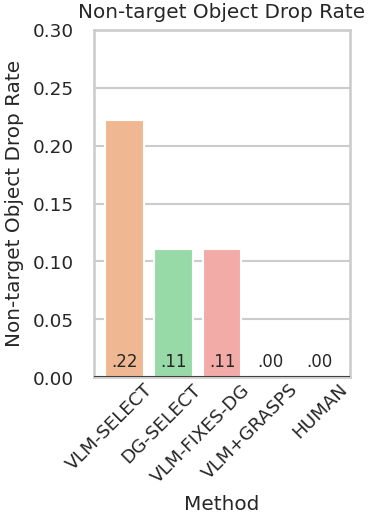
Robots must effectively retrieve novel objects in clutter, where a target may not be directly visible or accessible. In many real-world setups a robot must handle an open set of objects under constrained viewpoints and limited reachability; conditions often simplified in existing laboratory setups. Under these constraints, the robot must generate safe retrieval motions despite kinematic limitations and uncertainty regarding the novel objects’ shapes. This work proposes a complete modular pipeline to address such targeted object retrieval problems in clutter. The focus is on evaluating solutions for a critical component of this pipeline: reasoning about the order of blocking objects to be removed before the target is available to be retrieved. Vision-Language-Models (VLMs) have been recently argued as pretrained solutions that can reason about such spatial object relationships given RGB images. Traditional engineered solutions in this space aim to heuristically identify object relationships from depth. This work shows that pretrained VLMs alone (without finetuning) cannot yet outperform even random object selection. Engineering solutions are superior but also lead to a lot of failure cases. This work proposes hybrid strategies for targeted object retrieval that combine the visual reasoning of VLMs with engineered dependencies via 3D reasoning, which improve performance. These observations are confirmed in extensive physics-based simulation experiments and real world experiments for a setup involving a robotic arm with a parallel gripper and a torso-mounted stereo camera.